- 132
- Posts
- 9
- Years
- New Brunswick
- Seen May 6, 2023
I'm using a font editor to add some additional characters to pkmnem.tff, but the characters are still unrecognized and replaced with the undefined square symbol. When I use the updated .tff in a notepad app, the character works fine:

The ƒ works normally, but, in-game, is still undefined. I namely only care about the battle font:
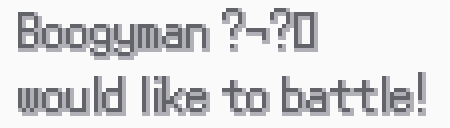
I want that square to be the ƒ, for example. I've defined the ƒ in both Power Green Small and Narrow as well, to no avail.
Here's a look at the font editor for a bit more insight:
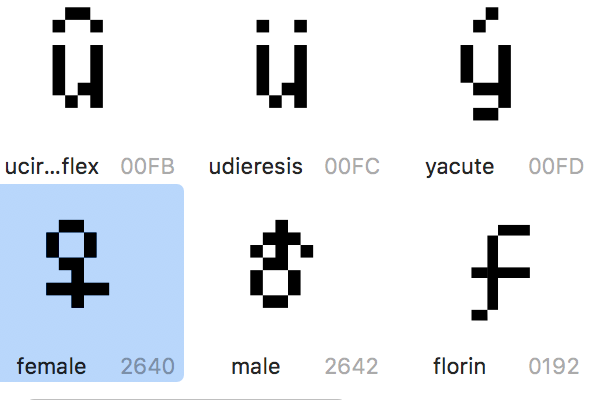
Interestingly enough, those male and female symbols come up as, not squares, but question marks in-game. Idk what that means.
Any help appreciated!
The ƒ works normally, but, in-game, is still undefined. I namely only care about the battle font:
I want that square to be the ƒ, for example. I've defined the ƒ in both Power Green Small and Narrow as well, to no avail.
Here's a look at the font editor for a bit more insight:
Interestingly enough, those male and female symbols come up as, not squares, but question marks in-game. Idk what that means.
Any help appreciated!


